
Cuda编程101
Cuda编程基本概念&编程模型
系列文章:
- Cuda编程101:Cuda编程的基本概念及编程模型
- Cuda编程102:Cuda程序性能相关话题
- Cuda编程103:Cuda多卡编程
- Cuda tips: nvcc的
-code、-arch、-gencode选项
基本想法
在介绍编码相关内容之前,一个更重要的话题是什么类型的问题适合用GPU进行解决。
GPU于CPU相比,有着惊人的核数、运算单元及内存带宽。对于给定问题,如果有办法把它分解为多个独立的子问题并行解决,那么GPU很有可能提供比CPU更好的性能。所谓“独立”,指的是所分解的子问题满足:
- 子问题之间尽可能避免同步
- 子问题之间尽可能依赖使用全局内存同步状态
- 子问题之间尽可能避免同步关系
矩阵相乘就是一个很好的例子,对矩阵相乘结果中各个元素的计算之间没有任何依赖关系,能够很好地通过GPU进行并行。当然对于一些问题,可能没办法立刻想出并行的办法,但是却存在可高效并行的问题分解办法,比方说:
(思考题)
- 归并两个有序数组
- 对一个数组求前缀和
对于手头的问题,如果能够顺利对问题进行分解,那么就有可能利用GPU提供的硬件特性及编程模型对其进行高效解决。
编程模型
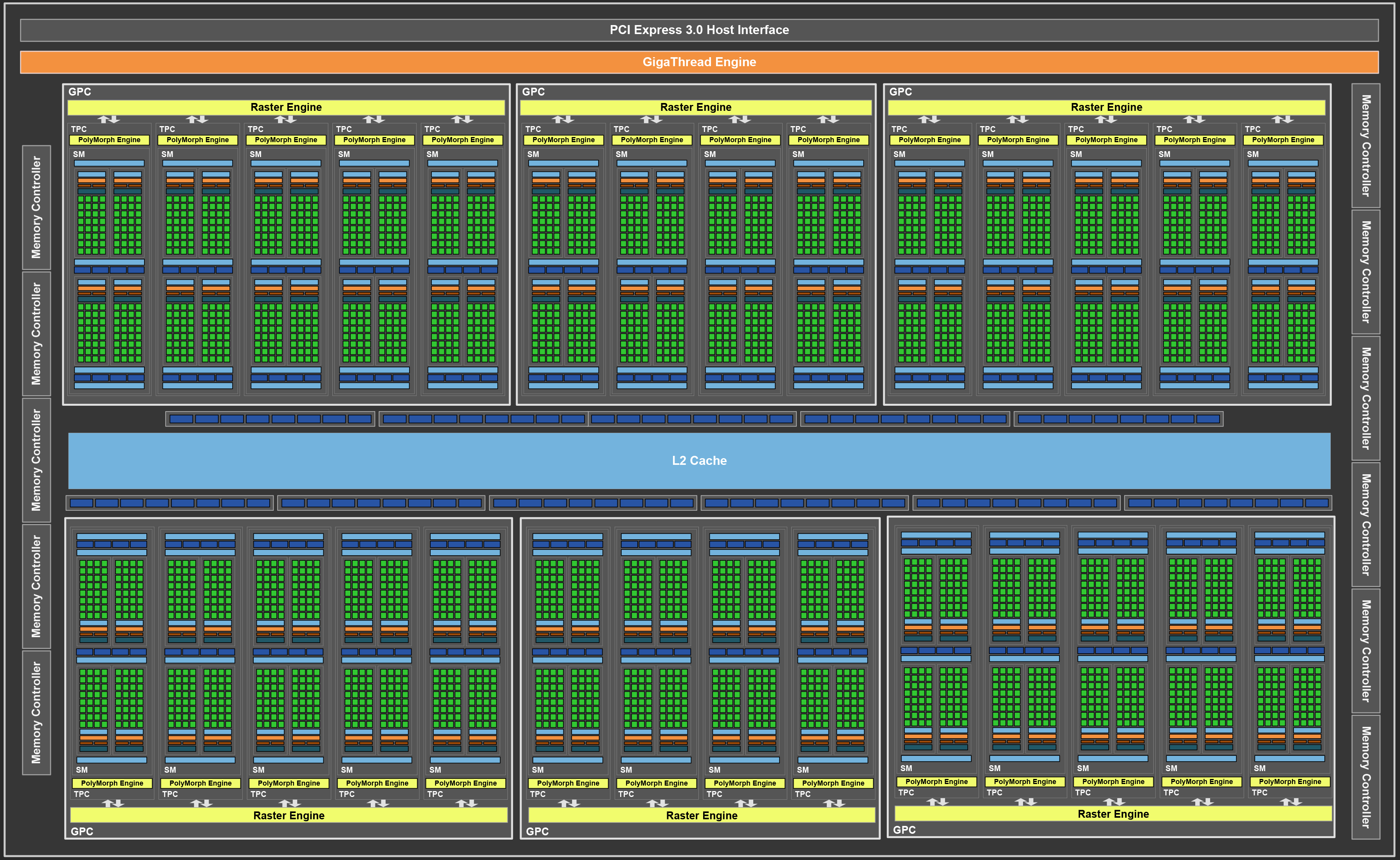
硬件视角
- 一块GPU上由多个Streaming Multiprocessors组成,简称SM。
- 每个SM中包含多个core,即实际完成计算的单元。
- 如下图所示,在一块1080ti上有28个SM,每个SM上有128个core,合计3584个cuda core。
编程视角
- 程序员编写一个在GPU由多个thread并行执行的函数,并从CPU代码对其调用。这样的函数我们将其称为一个kernel。
- 多个GPU thread组成一个thread block
- 对于一个kernel函数,程序员来指定启动多少个thread block,每个thread block里有多少thread
- 每个thread能够获取自己在哪个block中,以及自己是本block的第几个thread。对于一个并行处理任务,thread可根据这些信息确定自己应处理哪部分子问题。
执行视角
- 每个thread block会被调度到其中一个SM上执行
- 对于一个thread block中的各个thread,每32个thread组成一个warp,SM以warp为单位进行调度。在一个warp中,所有thread执行同一个指令流,即Single Instruction Multiple Thread(SIMT)。如果执行过程中有分支语句,那么执行不同分支的thread需要互相等待。比方说对于下列语句,任意时刻同一个warp中只能有一半的thread进行操作,而不是各自独立执行自己所在的分支。在写kernel时,不当的分支语句可能会导致性能下降。
if (threadIdx.x % 2 == 0) {
// Some work
} else {
// Other work
}
说点别的
32个thread组成的调度单元为什么叫warp?原因是thread有线的意思,而warp是织布机相关的一个把多个thread固定注的装置,于是就取了这个比喻:

资源限制
就像写CPU代码时会受到CPU核数、内存空间、访存速度的限制一样,GPU编程模型里也需要留意相关的资源限制:
- 每个thread block中的thread数量,1080ti的上限是1024
- 启动kernel时thread block数量(这个涉及到所起的thread block可能是多维的情况,先暂时认为是2147483647吧)
- 每个SM能同时处理的thread block数量,1080ti的上限是32
- Shared memory的大小,1080ti的上限是96kB
- GPU的访存速度,1080ti上限是484GB/s,如果真的受到了这个限制说明代码写得非常好了
- …(还有好多)
来点代码
CUDA编程中的常见流程是:
- 把CPU数据搬运到GPU中
- 写一个kernel定义我们想完成的计算
- 启动kernel
- 把运算结果从GPU搬运回CPU中
Cuda样例代码中的vectorAdd完成的任务是对长为numElements的两个数组h_A、h_B进行对应元素加合,并将结果存入h_C中。接下来我们以vectorAdd为例,说明这一流程:
- 首先是把CPU数据搬运到GPU中
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice); - 然后我们定义我们的加合计算
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements) { int i = blockDim.x * blockIdx.x + threadIdx.x; if (i < numElements) { C[i] = A[i] + B[i]; } }做的事情就是每个thread负责根据自己所在的thread block及threadIdx计算出自己所应处理的数组下标,并对这一下标对应的元素完成一次加合计算。
- 接下来我们启动kernel,其中
<<<blocksPerGrid, threadsPerBlock>>>指定了thread block数量及每个block中的thread数量。vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements); - 最后我们把运算结果搬运回CPU中。
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
一个cuda程序最重要的部分就完成了。完整代码中还包含了内存的分配、cuda调用的错误检查等内容,完整代码可见cuda安装目录下的samples/0_Simple/vectorAdd。
一些需要留意的地方
- kernel的执行是异步的,启动后会立即返回CPU代码中。如果计时的话会发现时间极短,其实这个时间仅仅是kernel启动的时间。
- 尽管kernel执行是异步的,然而cudaMemcpy又是阻塞的。
- 样例代码中的一次从CPU到GPU的cudaMemcpy调用其实完成了两次内存拷贝,一次从CPU原内存拷贝到了CPU中一段page-lock内存中,再从这段内存拷贝到GPU内存。
更多话题
- GPU的内存层级
- GPU访存pattern对性能的影响
- GPU的分支语句对性能的影响
- GPU中的同步操作、原子操作
- CPU、GPU间数据传输,PCIe,page-lock内存
- CUDA的debugger及profiler
思考题答案
- 归并两个有序数组:对于数组长度为n、m的有序数组及t个thread,可以对长为n的数组进行t等分,并对每一子数组的起终点,二分找到数组m中对应的上界及下界,并基于此进行并行归并。
- 对一个数组求前缀和: Parallel Prefix Sum (Scan) with CUDA