
Cuda编程102
Cuda程序性能提升
系列文章:
- Cuda编程101:Cuda编程的基本概念及编程模型
- Cuda编程102:Cuda程序性能相关话题
- Cuda编程103:Cuda多卡编程
- Cuda tips: nvcc的
-code、-arch、-gencode选项
Cuda为程序员使用GPU进行异构计算提供了抽象良好的编程模型。但正如同编写CPU程序时需注意局部性、缓存等硬件特性以获得更好地性能,为了更好地挖掘GPU的性能,我们在GPU程序中也需注意GPU特有的访存、执行、数据传输等方面的特性并进行相应的优化。
GPU的内存层级
和存在register、cache、DRAM这样的内存层级的CPU一样,GPU上也有着速度、大小各异的存储层级,由快至慢分别是:
- Register Files
- L1 / Shared Memory*
- L2 Cache
- Global Memory*
和CPU存在显著不同的是,在CPU程序中,通常只有DRAM是向程序员暴露的,如何使用各级缓存对程序中的变量进行缓存均由硬件决定;即使有register关键字,也只是一个hint而不是直接指定。而在GPU程序中,除了像CPU一样DRAM向程序员暴露之外,GPU中的L1/shared memory也是暴露给程序员使用的,即程序员可指定哪些数据放置于空间较大而延迟较高的global memory中,哪些数据放置于空间较小而延迟较低的shared memory中。
这一显著不同为程序员提供了重要的性能改进空间,如果能将占用空间较小而访问频率较高的数据存储于shared memory中,将可能显著改善程序性能。
举个例子,我们实现了两个完成M维向量点乘M*N维矩阵的kernel,其中multiply_without_shared直接访问global memory,而multiply_with_shared则在每个threadBlock内部将尺寸较小的向量拷贝至shared memory中:
__global__ void
multiply_without_shared(float* A, float* x, float* y, int N, int M) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= N) return;
int sum = 0;
for(int i = 0; i < M; ++i) {
sum += x[i] * A[i * M + idx];
}
y[idx] = sum;
}
__global__ void
multiply_with_shared(float* A, float* x, float* y, int N, int M) {
extern __shared__ float shared_x[];
if (threadIdx.x == 0) {
for(int i = 0; i < M; ++i) {
shared_x[i] = x[i];
}
}
__syncthreads();
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= N) return;
int sum = 0;
for(int i = 0; i < M; ++i) {
sum += shared_x[i] * A[i * M + idx];
}
y[idx] = sum;
}
在我的机器上,当设M=256,N=1000000时,multiply_with_shared相比于multiply_without_shared提供了4x的提速比。
GPU的分支语句对性能的影响
对于一个thread block中的各个thread,每32个thread组成一个warp,SM以warp为单位进行调度。在一个warp中,所有thread执行同一个指令流,即Single Instruction Multiple Thread(SIMT)。如果执行过程中有分支语句,那么执行不同分支的thread需要互相等待。比方说对于下列语句:
if (threadIdx.x % 2 == 0) {
// Some work
} else {
// Other work
}
任意时刻同一个warp中只能有一半的thread进行操作,而不是各自独立执行自己所在的分支,可能会导致速度下降至1/2。
那么这样的语句,大概会导致速度下降多少呢?
switch (threadIdx.x) {
case 0: ...
case 1: ...
...
case 126: ...
case 127: ...
}
答案是1/128?不对,应该是1/32,因为warp的组成是32个thread,这样的分支最多导致32叉的分叉。
GPU访存pattern对性能的影响
如前文所提到的,一个warp中的32个thread同时执行同一条instruction。当这32个thread同时执行一条内存读取指令时,GPU将发起一个或多个memory transaction。若这32个thread读取的是一段连续的内存,GPU将有机会在一个memory transaction中满足多个thread中的内存读取请求,从而减少memory transaction的数量且提高内存带宽的有效使用率。这种在连续thread中读取连续内存空间以提高内存带宽使用率的访存优化被称为memory coalescing。
举个例子,我们实现了两个实现向量加法的kernel,其中add_coalesced的相邻thread访问连续内存,而add_striped则跳跃访问内存:
__global__ void
add_coalesced(float* A, float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= N) return;
C[idx] = A[idx] + B[idx];
}
__global__ void
add_striped(float* A, float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + (threadIdx.x % 32) * 32 + (threadIdx.x / 32);
if (idx >= N) return;
C[idx] = A[idx] + B[idx];
}
在我的机器上,当设N=60M时,add_coalesced的执行速度是add_striped的3.5倍。
CPU、GPU间数据传输,PCIe,page-lock内存
CPU、GPU间的数据传输通过PCIe进行传输,目前服务器上常见的16x接口的理论带宽上限是16GB/s。CPU、GPU之间的所有数据传输均通过DMA完成,这就要求CPU侧的内存必须是page-lock的,而通常情况下我们向系统申请得到的内存均是pageable的,这就导致了当我们调用cudaMemcpy从CPU向GPU传输数据时,cudaMemcpy将执行以下判断:
- 若CPU内存是cuda runtime认为page-lock的,则直接发起DMA传输
- 若CPU内存是普通的pageable内存,则分配一段page-lock内存,将数据进行一次内存到内存的拷贝,再发起DMA传输
所谓“cuda runtime认为page-lock”的内存,是指该段内存由cudaMallocHost得到,或是一段普通内存但是曾对其调用过cudaHostRegister。
在我的机器上实测发现,对于相同大小的内存,对pageable内存调用cudaMemcpy的运行时间是对pagelock内存调用cudaMemcpy的3倍,即超过60%的时间花在了从原内存到page-lock内存的拷贝上。在这点上不注意的话,可能会得到PCIe的实际带宽远低于预期的结论,而真正的原因是有大量的时间被花在了将数据拷贝到page-lock内存的过程上。
值得一提的是cudaMallocHost可谓是惊人的慢。引用一个性能对比,如下图所示,malloc、cudaMallocHost分配相同大小内存的速度差异可以达到4个数量级。此外,分配过多的page-lock内存也会导致系统调度更加吃力并影响系统的性能。
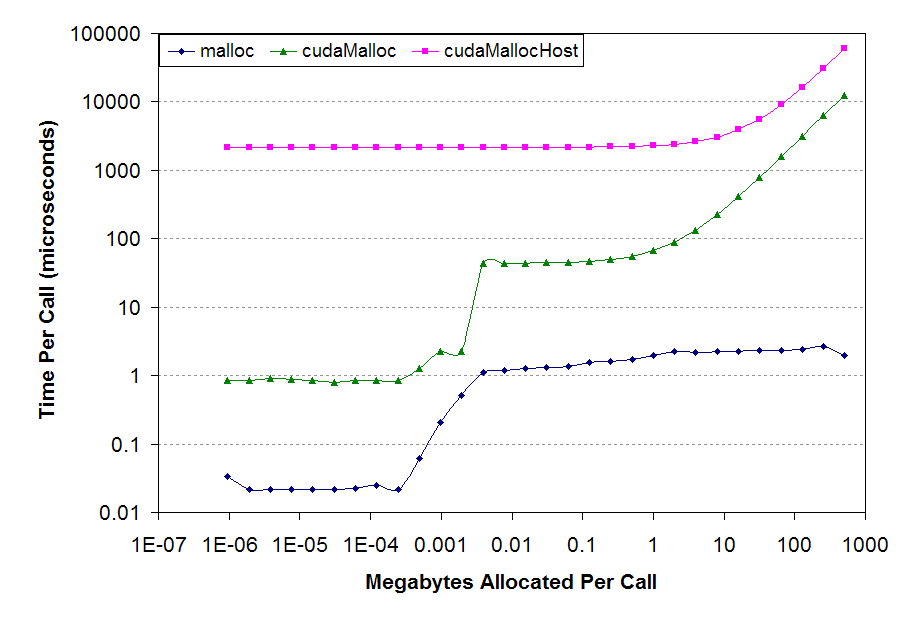
所以,对于CPU、GPU间数据传输这个问题,比较好的做法是是:
- 尽可能少传,宁可用计算换传输量
- 如果使用了
cudaMallocHost,尽可能重复使用以降低平均分配成本
总结
本文讨论了影响GPU程序执行性能的几个话题,涉及访存、执行、数据传输等多个方面,这些话题存在的原因来自于GPU、CPU架构之间的显著不同。尽管Cuda提供了抽象良好的编程模型,为了更好地挖掘GPU的性能,我们在编码时需要将GPU的架构纳入考虑并对上述话题进行留意。